
<머신러닝 • 딥러닝 문제해결 전략> 6장의 내용을 실습했습니다.
베이스라인 모델 훈련
베이스라인 모델이란 뼈대가 되는 가장 기본적인 모델을 뜻합니다. 이 베이스라인 모델에서 출발해 성능을 점차 향상시키는 방향으로 모델링해보도록 하겠습니다.
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/bike-sharing-demand/'
train = pd.read_csv(data_path + 'train.csv')
test = pd.read_csv(data_path + 'test.csv')
submission = pd.read_csv(data_path + 'sampleSubmission.csv')피처엔지니어링 (데이터 변환)
훈련 데이터와 테스트 데이터에 공통으로 반영해야 하기 때문에, 피처 엔지니어링 전에 두 데이터를 합치고 다 끝나면 도로 나눠줍니다.
이상치 제거
weather 4인 데이터가 이상치였기에 제거해야합니다.
# 훈련 데이터에서 weather가 4가 아닌 데이터만 추출
train = train[train['weather'] != 4]
데이터 합치기
훈련데이터와 테스트 데이터에 같은 피처를 적용하기 위해 두 데이터를 하나로 합쳐야 합니다. 이때 판다스의 concat() 함수를 사용하면 축을 따라 dataframe을 이어붙일 수 있습니다.
all_data_temp = pd.concat([train, test])
all_data_temp
원래 데이터의 인덱스를 무시하고 이어붙이려면 ignore_index = True를 전달하면 됩니다.
all_data = pd.concat([train, test], ignore_index=True)
all_data
파생 피처(변수) 추가
from datetime import datetime
# 날짜 피처 생성
all_data['date'] = all_data['datetime'].apply(lambda x: x.split()[0])
# 연도 피처 생성
all_data['year'] = all_data['datetime'].apply(lambda x: x.split()[0].split('-')[0])
# 월 피처 생성
all_data['month'] = all_data['datetime'].apply(lambda x: x.split()[0].split('-')[1])
# 시 피처 생성
all_data['hour'] = all_data['datetime'].apply(lambda x: x.split()[1].split(':')[0])
# 요일 피처 생성
all_data["weekday"] = all_data['date'].apply(lambda dateString : datetime.strptime(dateString, "%Y-%m-%d").weekday())
필요 없는 피처 제거
필요 없는 피처를 제거함으로써 사용할 피처를 모두 선별하였습니다.
drop_features = ['casual', 'registered', 'datetime', 'date', 'windspeed', 'month']
all_data = all_data.drop(drop_features, axis=1)
데이터 나누기
모든 피처엔지니어링을 적용했으므로 훈련데이터와 테스트 데이터를 다시 나눠야 합니다.
# 훈련 데이터와 테스트 데이터 나누기
X_train = all_data[~pd.isnull(all_data['count'])] # 타깃값이 있으면 훈련데이터, all_data['count': 타깃값, null이 아니면 훈련데이터 -> ~pd.isnull
X_test = all_data[pd.isnull(all_data['count'])] # 타깃값이 없으면 테스트데이터
# 타깃값 count 제거
X_train = X_train.drop(['count'], axis=1)
X_test = X_test.drop(['count'], axis=1)
y = train['count'] # 타깃값X_train.head()
처음 훈련 데이터와 비교하면 datetime, windspeed, casual, registered, count가 빠졌고 year, hour, weekday가 추가되었습니다.
평가지표 계산 함수 작성
경진대회 평가지표인 RMSLE를 계산하는 함수를 만들겠습니다.
import numpy as np
def rmsle(y_true, y_pred, convertExp=True):
# 지수변환
if convertExp:
y_true = np.exp(y_true)
y_pred = np.exp(y_pred)
# 로그변환 후 결측값을 0으로 변환
log_true = np.nan_to_num(np.log(y_true+1))
log_pred = np.nan_to_num(np.log(y_pred+1))
# RMSLE 계산
output = np.sqrt(np.mean((log_true - log_pred)**2))
return output타깃값이 count가 아닌 log(count)를 사용했기 때문에 y_true와 y_pred를 지수변환합니다. 지수변환에는 넘파이 내장 함수 exp()를 이용합니다. np.nan_to_num()함수는 NaN 결측값을 모두 0으로 바꾸는 기능을 합니다.
모델 훈련
가장 간단한 선형회귀 모델인 LinearRegression을 임포트하여 모델을 생성했습니다.
from sklearn.linear_model import LinearRegression
linear_reg_model = LinearRegression()훈련데이터로 모델을 훈련시킵니다.
log_y = np.log(y) # 타깃값 로그변환
linear_reg_model.fit(X_train, log_y) # 모델 훈련
모델 성능 검증
preds = linear_reg_model.predict(X_train)훈련된 선형회귀모델이 X_train 피처를 기반으로 타깃값을 예측합니다.
rmsle()함수의 세번째 인수로 true를 전달했으므로 rmsle 계산을 하기 전에 지수변환을 해줘야합니다.
:4.f는 소수점 넷째 자리까지 구하라는 명령입니다.
print (f'선형 회귀의 RMSLE 값: {rmsle(log_y, preds, True):.4f}')
예측 및 결과 제출
베이스라인 모델로 예측한 결과를 제출해보도록 하겠습니다. 이때 2가지를 주의해야합니다. 테스트 데이터로 예측한 결과를 이용해야 하고, 예측한 값에 지수변환을 해줘야 합니다.
linearreg_preds = linear_reg_model.predict(X_test) # 테스트 데이터로 예측
submission['count'] = np.exp(linearreg_preds) # 지수변환
submission.to_csv('submission.csv', index=False) # 파일로 저장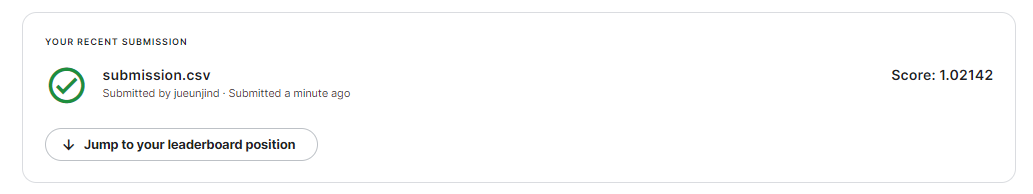
성능개선 1 : 릿지 회귀 모델
릿지 회귀 모델은 L2 규제를 적용한 선형 회쉬 모델입니다. (규제란 모델이 훈련 데이터에 과대 적합이 되지 않도록 해주는 방법이다.) 릿지회귀모델은 성능이 좋은 편이 아니라고 합니다.
하이퍼파라미터 최적화(모델 훈련)
릿지회귀모델에서는 하이퍼파라미터 최적화 단계에서 그리드 서치 기법을 사용합니다. 각 하이퍼파라미터를 적용한 모델마다 교차검증하며 성능을 측정해 최종적으로 성능이 가장 좋았을 때의 하이퍼파라미터 값을 찾아줍니다.
릿지 모델 생성
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
ridge_model = Ridge()
그리드서치 객체 생성
그리드서치를 하기 위해서 그리드서치 객체는 비교해볼 하이퍼파라미터 값 목록, 대상 모델, 교차 검증용 평가 수단(평가 함수) 3가지를 알아야 합니다. 대상 모델은 앞서 만들어 놓았기에 남은 두가지를 작성해 보았습니다.
# 하이퍼파라미터 값 목록
ridge_params = {'max_iter':[3000], 'alpha':[0.1, 1, 2, 3, 4, 10, 30, 100, 200,
300, 400, 800, 900, 1000]}
# 교차 검증용 평가 함수 (RMSLE 점수 계산)
rmsle_scorer = metrics.make_scorer(rmsle, greater_is_better=False)
# 그리드서치(with 릿지) 객체 생성
gridsearch_ridge_model = GridSearchCV(estimator=ridge_model, # 릿지 모델
param_grid=ridge_params, # 값 목록
scoring=rmsle_scorer, # 평가지표
cv=5) # 교차 검증 분할 수릿지 모델에서 중요한 하이퍼파라미터는 alpha로 값이 클 수록 규제강도가 세집니다. 즉 alpha를 적당한 크기로 하면 과대 적합문제를 개선할 수 있습니다.
그리드서치 수행
앞서 작성한 그리드서치 객체를 이용해 그리드 서치를 수행합니다.
log_y = np.log(y) # 타깃값 로그변환
gridsearch_ridge_model.fit(X_train, log_y) # 훈련 (그리드서치)print('최적 하이퍼파라미터 :', gridsearch_ridge_model.best_params_)
성능 검증
# 예측
preds =gridsearch_ridge_model.best_estimator_.predict(X_train)
# 평가
print(f'릿지 회귀 RMSLE 값 : {rmsle(log_y, preds, True):.4f}')
성능 개선2 : 라쏘 회귀 모델
라쏘 회귀모델은 L1 규제를 적용한 선형회귀모델입니다. 릿지회구모델과 마찬가지로 성능이 좋은 편이 아니라서 캐글러들이 잘 사용하지 않는다고 합니다. 릿지 회귀와 마찬가지로 alpha는 규제 강도를 조정하는 파라미터입니다.
from sklearn.linear_model import Lasso
# 모델 생성
lasso_model = Lasso()
# 하이퍼파라미터 값 목록
lasso_alpha = 1/np.array([0.1, 1, 2, 3, 4, 10 ,30, 100, 200, 300, 400, 800, 900, 1000])
lasso_params = {'max_iter':[3000], 'alpha':lasso_alpha}
# 그리드서치(with 라쏘) 객체 생성
gridsearch_lasso_model = GridSearchCV(estimator=lasso_model,
param_grid=lasso_params,
scoring=rmsle_scorer,
cv=5)
# 그리드서치 수행
log_y = np.log(y)
gridsearch_lasso_model.fit(X_train, log_y)
print('최적 하이퍼파라미터:', gridsearch_lasso_model.best_params_)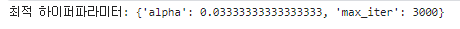
성능 검증
# 예측
preds = gridsearch_lasso_model.best_estimator_.predict(X_train)
# 평가
print(f'라쏘 회귀 RMSLE 값 : {rmsle(log_y, preds, True):.4f}')
성능개선3 : 랜덤 포레스트 회귀 모델
랜덤 포레스트 회귀는 훈련 데이터를 랜덤하게 샘플링한 모델 n개를 각각 훈련하여 결과를 평균하는 방법입니다.
하이퍼파라미터 최적화
랜덤 포레스트 회귀 모델로 그리드서치를 수행하고 최적 하이퍼파라미터 값을 출력해보았습니다.
그리드서치를 수행할 때 랜덤포레스트 회귀모델의 파라미터는 random_state (랜덤 시드값)과 n_estimators (랜덤포레스트를 구성하는 결정 트리 개수)입니다.
from sklearn.ensemble import RandomForestRegressor
# 모델 생성
randomforest_model = RandomForestRegressor()
# 그리드서치 객체 생성
rf_params = {'random_state': [42], 'n_estimators':[100, 120, 140]} #
gridsearch_random_forest_model = GridSearchCV(estimator=randomforest_model,
param_grid=rf_params,
scoring=rmsle_scorer,
cv=5)
#그리드서치 수행
log_y = np.log(y)
gridsearch_random_forest_model.fit(X_train, log_y)
print('최적 하이퍼파라미터: ', gridsearch_random_forest_model.best_params_)
모델 성능 검증
# 예측
preds = gridsearch_random_forest_model.best_estimator_.predict(X_train)
# 평가
print(f'랜덤 포레스트 회귀 RMSLE 값: {rmsle(log_y, preds, True):.4f}')
예측 및 결과 제출
import seaborn as sns
import matplotlib.pyplot as plt
randomforest_preds = gridsearch_random_forest_model.best_estimator_.predict(X_test)
figure, axes = plt.subplots(ncols=2)
figure.set_size_inches(10, 4)
sns.histplot(y, bins=50, ax=axes[0])
axes[0].set_title('Train Data Distribution')
sns.histplot(np.exp(randomforest_preds), bins=50, ax=axes[1])
axes[1].set_title('Predicted Test Data Distribution');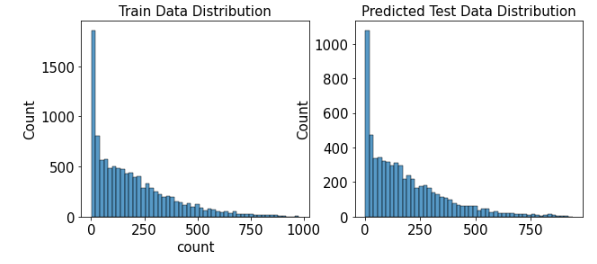
submission['count'] = np.exp(randomforest_preds) # 지수변환
submission.to_csv('submission.csv', index=False)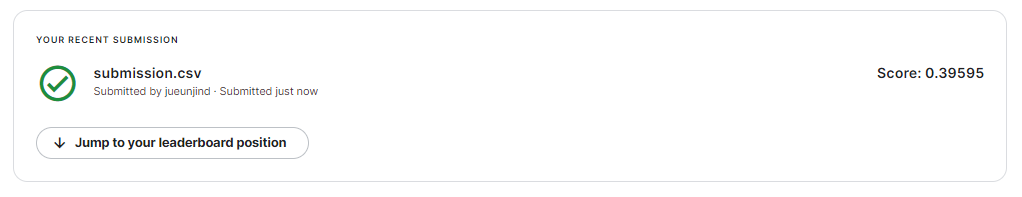
'Data > MLDL' 카테고리의 다른 글
| 안전 운전자 예측 경진대회: 베이스라인 모델 (0) | 2022.11.14 |
|---|---|
| 범주형 경진대회 이진분류 (0) | 2022.10.31 |
| 자전거 수요 예측 경진대회 (0) | 2022.09.26 |
| 하이퍼파라미터 최적화 (0) | 2022.09.19 |
| 주요 머신러닝 모델 (0) | 2022.09.19 |