
<머신러닝 • 딥러닝 문제해결 전략> 8장의 내용을 실습했습니다.
이번 모델은 베이스라인 모델과 같은 lightgbm 모델을 그대로 사용하되, 피처엔지니어링과 하이퍼파라미터 최적화를 추가로 적용한 모델입니다. 피처엔지니어링 과정에서 명목형피처 원핫인코딩 & 필요없는 피처제거 사이에 파생 피처를 추가하고, 모델 훈련과정에서 베이지안 최적화를 추가하여 실습해보았습니다.
# 데이터 호출
import pandas as pd
# 데이터 경로
data_path = '/kaggle/input/porto-seguro-safe-driver-prediction/'
train = pd.read_csv(data_path + 'train.csv', index_col='id')
test = pd.read_csv(data_path + 'test.csv', index_col='id')
submission = pd.read_csv(data_path + 'sample_submission.csv', index_col='id')1. 피처 엔지니어링
데이터 합치기
all_data = pd.concat([train, test], ignore_index=True)
all_data = all_data.drop('target', axis=1) # 타깃값 제거
all_features = all_data.columns # 전체 피처명목형 피처 원핫 인코딩
from sklearn.preprocessing import OneHotEncoder
# 명목형 피처
cat_features = [feature for feature in all_features if 'cat' in feature]
# 원-핫 인코딩 적용
onehot_encoder = OneHotEncoder()
encoded_cat_matrix = onehot_encoder.fit_transform(all_data[cat_features])파생 피처 추가
결측값 개수를 파생피처로 추가해봅니다.
결측값 개수를 num_missing이라는 피처명으로 all_data에 추가했습니다.
# '데이터 하나당 결측값 개수'를 파생 피처로 추가
all_data['num_missing'] = (all_data==-1).sum(axis=1)방금 생성한 파생피처 num_missing을 remaining_features에 추가합니다.
# 명목형 피처, calc 분류의 피처를 제외한 피처
remaining_features = [feature for feature in all_features
if ('cat' not in feature and 'calc' not in feature)]
# num_missing을 remaining_features에 추가
remaining_features.append('num_missing')모든 ind 피처값을 연결하여 새로운 피처를 만들어냅니다. 이 피처명을 mix_ind라고 하겠습니다. 이 피처 자체는 임시 피처로, 이것을 활용해 또 다른 새로운 피처를 만들어 낼 것입니다. 명목형 별 고유값 별 개수를 만들어봅시다.
먼저 분류가 ind인 피처들을 추출하고, 그 다음 피처들을 순회하면서 모든 값을 연결하면 됩니다.
# 분류가 ind인 피처
ind_features = [feature for feature in all_features if 'ind' in feature]
is_first_feature = True
for ind_feature in ind_features:
if is_first_feature:
all_data['mix_ind'] = all_data[ind_feature].astype(str) + '_'
is_first_feature = False
else:
all_data['mix_ind'] += all_data[ind_feature].astype(str) + '_'새로운 피처 mix_ind 를 만들었습니다.
all_data['mix_ind']
명목형 피처의 고유값별 개수를 새로운 피처로 추가합니다. 고유값별 개수는 value_count()로 구합니다.
value_count()는 series 타입을 반환하기 때문에 series 타입을 딕셔너리로 바꾸기 위한 to_dict()를 호출합니다.
all_data['ps_ind_02_cat'].value_counts().to_dict()
이 코드를 활용해 명목형 피처의 고유값별 개수를 파생 피처로 만들어 보겠습니다. cat 분류에 속하는 피처들과 mix_ind 피처를 모두 명목형 피처로 간주하겠습니다.
cat_count_features = []
for feature in cat_features+['mix_ind']:
val_counts_dict = all_data[feature].value_counts().to_dict()
all_data[f'{feature}_count'] = all_data[feature].apply(lambda x:
val_counts_dict[x])
cat_count_features.append(f'{feature}_count')cat_count_features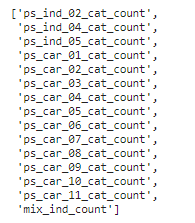
# 필요없는 피처들 제거 후 피처 엔지니어링 한 지금까지의 모든 데이터 합침
from scipy import sparse
# 필요 없는 피처들
drop_features = ['ps_ind_14', 'ps_ind_10_bin', 'ps_ind_11_bin',
'ps_ind_12_bin', 'ps_ind_13_bin', 'ps_car_14']
# remaining_features, cat_count_features에서 drop_features를 제거한 데이터
all_data_remaining = all_data[remaining_features+cat_count_features].drop(drop_features, axis=1)
# 데이터 합치기
all_data_sprs = sparse.hstack([sparse.csr_matrix(all_data_remaining),
encoded_cat_matrix],
format='csr')데이터 나누기
num_train = len(train) # 훈련 데이터 개수
# 훈련 데이터와 테스트 데이터 나누기
X = all_data_sprs[:num_train]
X_test = all_data_sprs[num_train:]
y = train['target'].values2. 하이퍼파라미터 최적화
데이터셋 준비
베이지안 최적화를 위한 데이터셋을 만드는 과정입니다.
import lightgbm as lgb
from sklearn.model_selection import train_test_split
# 8:2 비율로 훈련 데이터, 검증 데이터 분리 (베이지안 최적화 수행용)
X_train, X_valid, y_train, y_valid = train_test_split(X, y,
test_size=0.2,
random_state=0)
# 베이지안 최적화용 데이터셋
bayes_dtrain = lgb.Dataset(X_train, y_train)
bayes_dvalid = lgb.Dataset(X_valid, y_valid)하이퍼파라미터 범위 설정
# 베이지안 최적화를 위한 하이퍼파라미터 범위
param_bounds = {'num_leaves': (30, 40),
'lambda_l1': (0.7, 0.9),
'lambda_l2': (0.9, 1),
'feature_fraction': (0.6, 0.7),
'bagging_fraction': (0.6, 0.9),
'min_child_samples': (6, 10),
'min_child_weight': (10, 40)}
# 값이 고정된 하이퍼파라미터
fixed_params = {'objective': 'binary', # 이진분류
'learning_rate': 0.005, # 학습률 보통 0.01~0.001 사이의 값으로 지정
'bagging_freq': 1, # 배깅빈도 임의로 1로 지정
'force_row_wise': True,
'random_state': 1991} # 값을 고정시켜 다시 돌려도 동일한 결과 나오도록 함베이지안 최적화용 평가지표 계산함수 작성
eval_function()은 베이지안 최적화를 수행하기 위한 평가지표(지니계수) 계산함수입니다. 이 함수로 지니계수를 계산해 최적 하이퍼파라미터를 찾습니다. 최적화하려는 lightgbm 모델의 하이퍼파라미터 7개의 인수로 받고 지니계수를 반환합니다.
def eval_function(num_leaves, lambda_l1, lambda_l2, feature_fraction,
bagging_fraction, min_child_samples, min_child_weight):
'''최적화하려는 평가지표(지니계수) 계산 함수'''
# 베이지안 최적화를 수행할 하이퍼파라미터 # 1 최적화할 하이퍼파라미터 정의
params = {'num_leaves': int(round(num_leaves)), # int(round(num_leaves) 실수형을 정수형으로 바꾸는 코드
'lambda_l1': lambda_l1,
'lambda_l2': lambda_l2,
'feature_fraction': feature_fraction,
'bagging_fraction': bagging_fraction,
'min_child_samples': int(round(min_child_samples)),
'min_child_weight': min_child_weight,
'feature_pre_filter': False}
# 고정된 하이퍼파라미터도 추가 # 2
params.update(fixed_params)
print('하이퍼파라미터:', params)
# LightGBM 모델 훈련 # 3
lgb_model = lgb.train(params=params,
train_set=bayes_dtrain,
num_boost_round=2500,
valid_sets=bayes_dvalid,
feval=gini,
early_stopping_rounds=300,
verbose_eval=False)
# 검증 데이터로 예측 수행 # 4
preds = lgb_model.predict(X_valid)
# 지니계수 계산 # 5
gini_score = eval_gini(y_valid, preds)
print(f'지니계수 : {gini_score}\n')
return gini_score # 6 지니계수 반환# 1: eval_function()에 인수로 전달되는 값 모두 실수형이 되기 때문에
int(round(num_leaves) 정수형으로 바꾸는 코드를 사용해 정수형으로 바꿔줌.
# 2: 고정 하이퍼파라미터(fixed_params)를 추가. params는 딕셔너리 타입이기 때문에 update()함수로 원소를 추가해줌.
최적화 수행
베이지안 최적화 객체를 생성. 생성파라미터로 eval_function과 param_bounds를 전달한다.
from bayes_opt import BayesianOptimization
# 베이지안 최적화 객체 생성
optimizer = BayesianOptimization(f=eval_function, # 평가지표 계산 함수
pbounds=param_bounds, # 하이퍼파라미터 범위
random_state=0)maxmize() 메서드를 호출해 베이지안 최적화를 수행한다.
# 베이지안 최적화 수행
optimizer.maximize(init_points=3, n_iter=6)
# init_points 무작위로 하이퍼파라미터 탐색하는 횟수
# n_iter 베이지안 최적화 반복 횟수
# 베이지안 최적화는 init_points와 n_iter 더한 값만큼 반복됨.결과확인
최적화가 끝나면 최적하이퍼파라미터(지니계수가 최대가 되는 하이퍼파라미터)를 출력해봅니다.
# 평가함수 점수가 최대일 때 하이퍼파라미터
max_params = optimizer.max['params']
max_params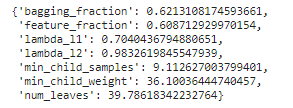
이중 num_leaves와 min_child_samples는 원래 정수형 하이퍼파라미터이므로 정수형으로 변환하여 다시 저장합니다.
# 정수형 하이퍼파라미터 변환
max_params['num_leaves'] = int(round(max_params['num_leaves']))
max_params['min_child_samples'] = int(round(max_params['min_child_samples']))여기에 고정된 하이퍼파라미터들도 추가합니다.
# 값이 고정된 하이퍼파라미터 추가
max_params.update(fixed_params)최종 하이퍼파라미터를 출력해봅니다.
max_params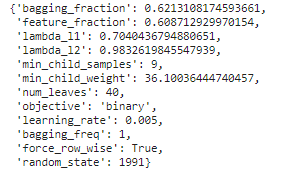
3. 모델 훈련 및 성능 검증
from sklearn.model_selection import StratifiedKFold
# 층화 K 폴드 교차 검증기 생성
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=1991)
# OOF 방식으로 훈련된 모델로 검증 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_val_preds = np.zeros(X.shape[0])
# OOF 방식으로 훈련된 모델로 테스트 데이터 타깃값을 예측한 확률을 담을 1차원 배열
oof_test_preds = np.zeros(X_test.shape[0])
# OOF 방식으로 모델 훈련, 검증, 예측
for idx, (train_idx, valid_idx) in enumerate(folds.split(X, y)):
# 각 폴드를 구분하는 문구 출력
print('#'*40, f'폴드 {idx+1} / 폴드 {folds.n_splits}', '#'*40)
# 훈련용 데이터, 검증용 데이터 설정
X_train, y_train = X[train_idx], y[train_idx] # 훈련용 데이터
X_valid, y_valid = X[valid_idx], y[valid_idx] # 검증용 데이터
# LightGBM 전용 데이터셋 생성
dtrain = lgb.Dataset(X_train, y_train) # LightGBM 전용 훈련 데이터셋
dvalid = lgb.Dataset(X_valid, y_valid) # LightGBM 전용 검증 데이터셋
# LightGBM 모델 훈련
lgb_model = lgb.train(params=max_params, # 최적 하이퍼파라미터 # 1
train_set=dtrain, # 훈련 데이터셋
num_boost_round=2500, # 부스팅 반복 횟수
valid_sets=dvalid, # 성능 평가용 검증 데이터셋
feval=gini, # 검증용 평가지표
early_stopping_rounds=300, # 조기종료 조건
verbose_eval=100) # 100번째마다 점수 출력
# 테스트 데이터를 활용해 OOF 예측
oof_test_preds += lgb_model.predict(X_test)/folds.n_splits
# 모델 성능 평가를 위한 검증 데이터 타깃값 예측
oof_val_preds[valid_idx] += lgb_model.predict(X_valid)
# 검증 데이터 예측확률에 대한 정규화 지니계수
gini_score = eval_gini(y_valid, oof_val_preds[valid_idx])
print(f'폴드 {idx+1} 지니계수 : {gini_score}\n')lightgbm 훈련 시 사용한 파라미터만 max_params로 바꿨을 뿐 베이스라인과 모델훈련코드 비슷함.
print('OOF 검증 데이터 지니계수 :', eval_gini(y, oof_val_preds))
submission['target'] = oof_test_preds
submission.to_csv('submission.csv')

성능이 개선된 것을 확인할 수 있다.
'Data > MLDL' 카테고리의 다른 글
| 향후 판매량 예측 경진대회 (0) | 2022.11.21 |
|---|---|
| 안전 운전자 예측 경진대회: 성능개선2(XGBoost 모델) (0) | 2022.11.14 |
| 안전 운전자 예측 경진대회: 베이스라인 모델 (0) | 2022.11.14 |
| 범주형 경진대회 이진분류 (0) | 2022.10.31 |
| 자전거 대여 수요 예측(2) (0) | 2022.09.26 |