
<머신러닝 • 딥러닝 문제해결 전략> 5장의 내용을 실습했습니다.
선형 회귀 모델
독립변수 x와 종속변수 y의 관계를 선형으로 모델링한 것 ( y = wx +b)
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0) # 시드값 고정
w0 = 5 # y절편
w1 = 2 # 회귀계수
noise = np.random.randn(100, 1) # 노이즈, 표준정규분포를 따르는 데이터 100개를 생성
x = 4 * np.random.rand(100, 1) # 0~4 사이 실숫값 100개 생성 (x값)
y = w1*x + w0 + noise # y값
plt.scatter(x, y);# np.random.rand(100, 1) : 0~1 사이의 무작위값 100개 생성, 독립변수 x값을 100개 만드는 코드임

위 데이터를 이용해 선형 회귀 모델을 훈련시켜보았습니다. 모델 훈련을 통해 적절한 회귀계수와 y절편 값을 찾아보도록 합시다.
from sklearn.linear_model import LinearRegression
linear_reg_model = LinearRegression()
linear_reg_model.fit(x, y)
print('y절편(w0):', linear_reg_model.intercept_)
print('회귀계수(w1):', linear_reg_model.coef_)
선형회귀 모델의 회귀선을 그리기 위해 예측값을 이용해 실습해보았습니다.
y_pred = linear_reg_model.predict(x)
plt.scatter(x, y)
plt.plot(x, y_pred);
로지스틱 회귀 모델
선형 회귀 방식을 응용해 분류에 적용한 모델이다. 스팸 메일 분류와 같은 이진 분류 문제에 로지스틱 회귀를 사용할 수 있다. 로지스틱 회귀는 시그모이드 함수를 활용해 타깃값에 포함될 확률을 예측한다.
시그모이드 함수는 0에서 1 사이 값을 갖는다. x값이 작을수록 0에 가깝고, 클수록 1에 가깝다. x가 0일 땐 0.5이다.
이진 분류 모델에서 시그모이드(확률) 값이 0.5보다 작으면 0(음성), 0.5이상이면 1(양성)이라고 예측하기에 타깃값 예측도 간단하다.
결정 트리
분류와 회귀 문제 모두 사용 가능한 모델이다.

결정트리는 데이터를 어떤 조건으로 분할하는지에 따라 트리 모양과 동작 효율이 달라진다.
머신러닝에서 결정트리는 노드 내 데이터의 불순도를 최소화하는 방법으로 분할한다.
(불순도란 한 범주안에서 서로 다른 데이터가 얼마나 섞여있는지를 나타내는 정도이다.)
한 범주에 데이터가 한 가지 종류만 있다면 불순도가 최소 (혹은 순도 최대)이고,
서로 다른 데이터가 같은 비율로 섞여있다면 불순도가 최대 (혹은 순도 최소)이다.
불순도를 측정하는 지표로는 엔트로피와 지니 불순도가 있다.
엔트로피란 '불확실한 정도'를 뜻한다. 한 범주에 데이터가 한 종류만 있다면 어떤 데이터를 고르든 그 종류를 확실하게 말할 수 있기에 엔트로피는 0이다. (반대로 서로 다른 데이터의 비율이 비등해질수록 엔트로피는 1에 가까워진다.)
즉, 엔트로피 값이 클수록 불순도가 높고, 엔트로피 값이 작을수록 불순도도 낮아진다.
(1 - 엔트로피)를 정보 이득이라고 하는데, 결정트리는 정보 이득을 최대화하는 방향(엔트로피를 최소화)으로 노드를 분할한다.
지니 불순도도 엔트로피와 비슷한 개념으로, 값이 클수록 불순도가 높고 작을수록 불순도가 낮다.
사이킷런으로 결정트리를 구현할 수 있다. 분류용 모델은 DecisionTreeClassifier, 회귀용 모델은 DecisionTreeRegressor입니다. 분류 모델인 DecisionTreeClassifier로 결정트리 구현을 실습해보았습니다.
DecisionTreeClassifier의 파라미터들
- criterion : 분할 시 사용할 불순도 측정 지표
- max_depth : 트리의 최대 깊이
- min_samples_split : 노드 분할을 위한 최소 데이터 개수
- min_samples_leaf : 말단 노드가 되기 위한 최소 데이터 개수
- max_features : 분할에 사용할 피처 개수
결정트리에 조건이 많을수록 분할이 많고 트리가 깊어진다. 분할을 지나치게 많이 할 경우 모델이 과대적합될 수 있다. 이 경우 max_depth, min_samples_split, min_samples_leaf 결정트리의 과대적합을 제어하는 파라미터를 이용하면 된다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
# 유방암 데이터 불러오기
cancer_data = load_breast_cancer()
# 훈련, 테스트 데이터로 분리
X_train, X_test, y_train, y_test = train_test_split(cancer_data['data'],
cancer_data['target'],
stratify=cancer_data['target'],
test_size=0.4,
random_state=42)
decisiontree = DecisionTreeClassifier(random_state=42) # 결정트리 정의
decisiontree.fit(X_train, y_train) # 모델 훈련
accuracy = decisiontree.score(X_test, y_test) # 정확도 측정
# 테스트 데이터로 활용하여 결정트리 모델 정확도 출력
print(f'결정 트리 정확도: {accuracy:.3f}')
앙상블 학습
앙상블 학습은 다양한 모델이 내린 예측 결과를 결합하는 기법이다. 머신러닝에서 앙상블 학습을 활용하면 대체로 예측성능이 좋아지고, 과대 적합을 방지할 수 있다. 앙상블 학습의 유형으로는 보팅, 배깅, 부스팅 등이 있다.
보팅
서로 다른 모델로 예측한 결과가 여럿 있을 때 개별결과를 종합해 최종 결과를 결정하는 방식이다.
- 하드 보팅 : 다수결 투표 방식으로 최종 예측값을 정함. 모델 1,2,3 이 1로 예측하고 모델 4,5가 0으로 예측할 경우 다수결에 의해 1이 최종 예측값으로 선정
- 소프트 보팅 : 개별 예측 확률들의 평균을 최종 예측확률로 정하는 방식
하드보팅보다 소프트 보팅이 성능이 좋아서 대체로 소프트 보팅을 사용한다.
배깅
개별 모델이 서로 다른 샘플링 데이터를 활용하여, 예측한 결과를 결합해 최종 예측을 정하는 기법
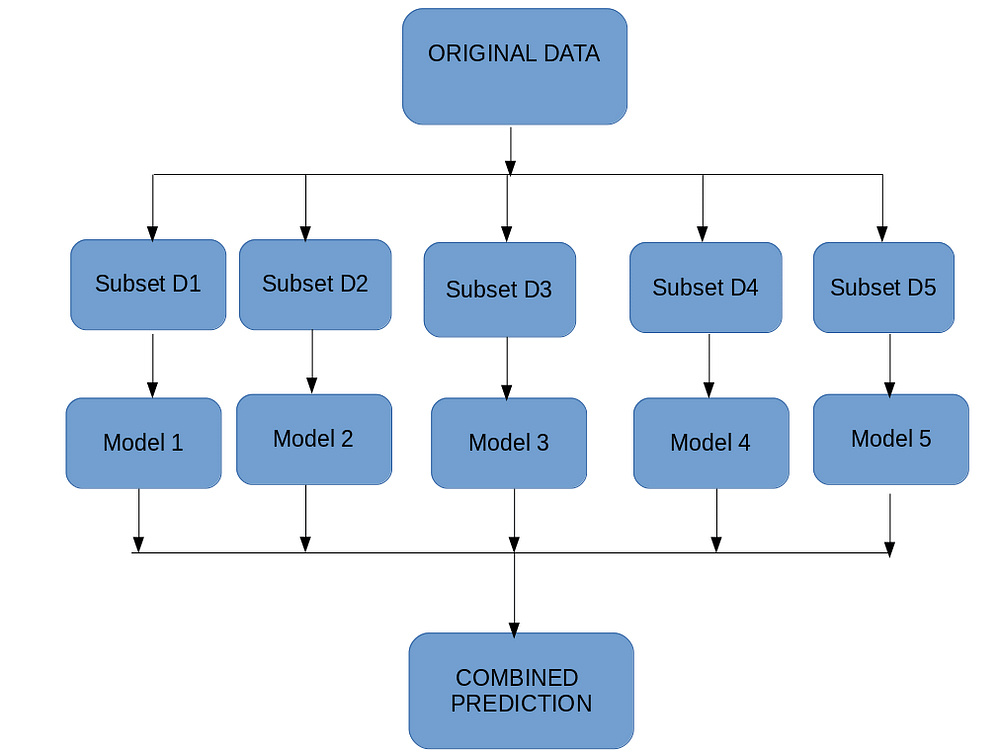
보팅 방식으로 최종 예측값을 결정한다. 배깅은 원리가 간단하면서 성능을 높일 수 있는 효과적인 기법임. 대표적인 예시가 랜덤 포레스트이다.
부스팅
가중치를 활용해 분류 성능이 약한 모델을 강하게 만드는 기법이다.
1. 원본 데이터 셋을 준비해 처음에는 동일한 가중치를 주고 분류를 진행한다.
2. 분류모델 1이 잘못 분류한 데이터에 더 높은 가중치를 부여한다.
3. 분류모델 2는 가중치가 부여된 데이터에 집중해 데이터를 분류한다.
4. 분류모델2가 잘못 분류한 데이터에 더욱 높은 가중치를 부여한다.
5. 분류모델 3은 이전 단계에서 가중치가 부여된 데이터에 집중해 데이터를 분류한다.
이 절차대로 개별 분류모델 3개를 구했습니다. 분류모델 1, 2, 3을 결합하면 제대로 구분하는 모델을 만들 수 있습니다.
부스팅 기법의 예시로는 XGBoost, LightGBM 등이 있다.
랜덤 포레스트
결정트리를 배깅 방식으로 결합한 모델이다.
랜덤 포레스트의 분류 모델은 RandomForestClassifier, 회귀모델은 RandomForestRegressor입니다. 회귀모델을 이용해 실습을 진행했습니다.
RandomForestClassifier의 파라미터
- n_estimators : 랜덤 포레스트를 구성할 결정트리 개수
- criterion : 분할 시 사용할 불순도 측정 지표
- max_depth : 트리의 최대 깊이
- min_samples_split : 노드 분할을 위한 최소 데이터 개수
- min_samples_leaf : 말단 노드가 되기위한 최소 데이터 개수
- max_features : 분할에 사용할 피처 개수
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
#유방암 데이터 불러오기
cancer_data = load_breast_cancer()
# 훈련, 테스트 데이터로 분리
X_train, X_test, y_train, y_test = train_test_split(cancer_data['data'],
cancer_data['target'],
stratify=cancer_data['target'],
test_size=0.4,
random_state=42)
randomforest = RandomForestClassifier(random_state=42) # 랜덤 포레스트 정의
randomforest.fit(X_train, y_train) # 모델 훈련
accuracy = randomforest.score(X_test, y_test) # 정확도 측정
# 테스트 데이터를 활용하여 랜덤 포레스트 모델 정확도 출력
print(f'랜덤 포레스트 정확도: {accuracy:.3f}')
XGBoost
결정트리를 부스팅 방식으로 결합한 모델이다. 부스팅 방식이기 때문에 직전 트리가 예측한 값을 다음 트리가 활용해서 예측값을 조금씩 수정한다.
파이썬 래퍼 XGBoost를 사용하려면 DMatrix 객체를 활용해 XGBoost 전용 데이터 셋을 만들어야한다.
xgboost.DMatrix() 파라미터
- data : xgboost.DMatrix용 데이터셋, 문자열 타입 전달할 수 있다
- label : 타깃값
- booster : 부스팅 알고리즘
- objective : 훈련 목적
- eta (learning_rate) : 학습률. 0~1 사이 값으로 설정할 수 있고, 일반적으로 0.0001~0.1 사이 값을 사용. 기본값이 0.3이다.
- max_depth : 개별 트리의 최대 깊이
- subsample : 개별 트리를 훈련할 때 사용할 데이터 샘플링 비율
- colsample_bytree : 개별 트리를 훈련할 때 사용하는 피처 샘플링 비율
- alpha (reg_alpha) : L1 규제조정값
- lambda (reg_lambda) : L2 규제조정값
- gamma (min_split_loss) : 말단 노드가 분할하기 위한 최소 손실 감소 값
- min_child_weight : 과대 적합 방지를 위한 값
- scale_pos_weight : 불균형 데이터 가중치 조정값
- random_state : 랜덤 시드값 (코드를 반복실행해도 같은 결과가 나오게 지정하는 값)
xgboost.train() 파라미터
- params : xgboost 모델의 하이퍼파라미터 목록
- dtrain : 훈련 데이터셋
- num_boost_round : 부스팅 반복횟수
- evals : 모델 성능 평가용 검증 데이터셋
- faval : 검증용 평가지표
- maximize : feval 평가 점수가 높은지 좋은지 여부를 True, False로 전달
- early_stopping_rounds : 조기종료 조건
- verbose_eval : 성능 점수 로그 설정 값
LightGBM
XGBoost와 성능은 비슷하지만 훈련속도가 더 빨라서 많이 사용되는 머신러닝 모델이다.
LightGBM은 말단 노드 중심으로 예측오류를 최소화하게끔 분할한다. 균형을 유지할 필요가 없으니 추가 연산이 필요없다. 그래서 더 빠르다. 하지만 데이터 개수가 적을 경우 과대 적합이 되기 쉽다는 단점이 생긴다. 이 때 과대적합 방지용 하이퍼파라미터를 조정해줘야 한다.
LightGBM.dataset() 파라미터
- data : 데이터 셋
- label : 타깃값
- boosting_type : 부스팅 알고리즘
- objective : 훈련 목적
- learning_rate : 학습률
- num_leaves : 개별 트리가 가질 수 있는 최대 말단 개수
- max_depth : 개별 트리의 최대 깊이
- bagging_fraction (subsample): 개별 트리를 훈련할 때 사용할 데이터 샘플링 비율
- feature_fraction (colsample_bytree) : 개별 트리를 훈련할 때 사용하는 피처 샘플링 비율
- lambda_l1 (reg_alpha) : L1 규제 조정값
- lambda_l2 (reg_lambda) : L2 규제 조정값
- min_child_samples : 말단 노드가 되기 위해 필요한 최소 데이터 개수
- min_child_weight : 과대적합 방지를 위한 값
- bagging_freq (subsample_freq) : 배깅 수행 빈도
- force_row_wise : 메모리 용량이 충분하지 않을 때 메모리 효율을 높이는 파라미터
- random_state : 랜덤 시드값
LightGBM.train() 파라미터
- params : LightGBM 모델의 하이퍼파라미터 목록
- trian_set : 훈련 데이터셋
- num_boost_round : 부스팅 반복 횟수
- valid_sets : 모델 성능 평가용 검증 데이터셋
- feval : 검증용 평가지표
- category_feature : 범주형 데이터 파라미터
- early_stopping_rounds : 조기 종료 조건
- verbose_eval : 성능 점수 로그 설정 값
'Data > MLDL' 카테고리의 다른 글
| 범주형 경진대회 이진분류 (0) | 2022.10.31 |
|---|---|
| 자전거 대여 수요 예측(2) (0) | 2022.09.26 |
| 자전거 수요 예측 경진대회 (0) | 2022.09.26 |
| 하이퍼파라미터 최적화 (0) | 2022.09.19 |
| 교차검증 (0) | 2022.09.19 |